
January 3, 2026
In the world of 2026 enterprise AI, Retrieval-Augmented Generation (RAG) is the engine of productivity. It allows your LLM to step outside its static training data and "read" your company’s real-time documents, wikis, and databases. But there is a massive catch: if the AI can read it, the AI can speak it.
LLM02: Sensitive Information Disclosure occurs when an AI reveals private data—ranging from PII (Personally Identifiable Information) to trade secrets—that it was never meant to share. Within a robust AI Security Framework, securing the RAG pipeline is the most critical step in maintaining data privacy.
Data leakage in AI isn't usually the result of a "hack" in the traditional sense; it’s a failure of context management.
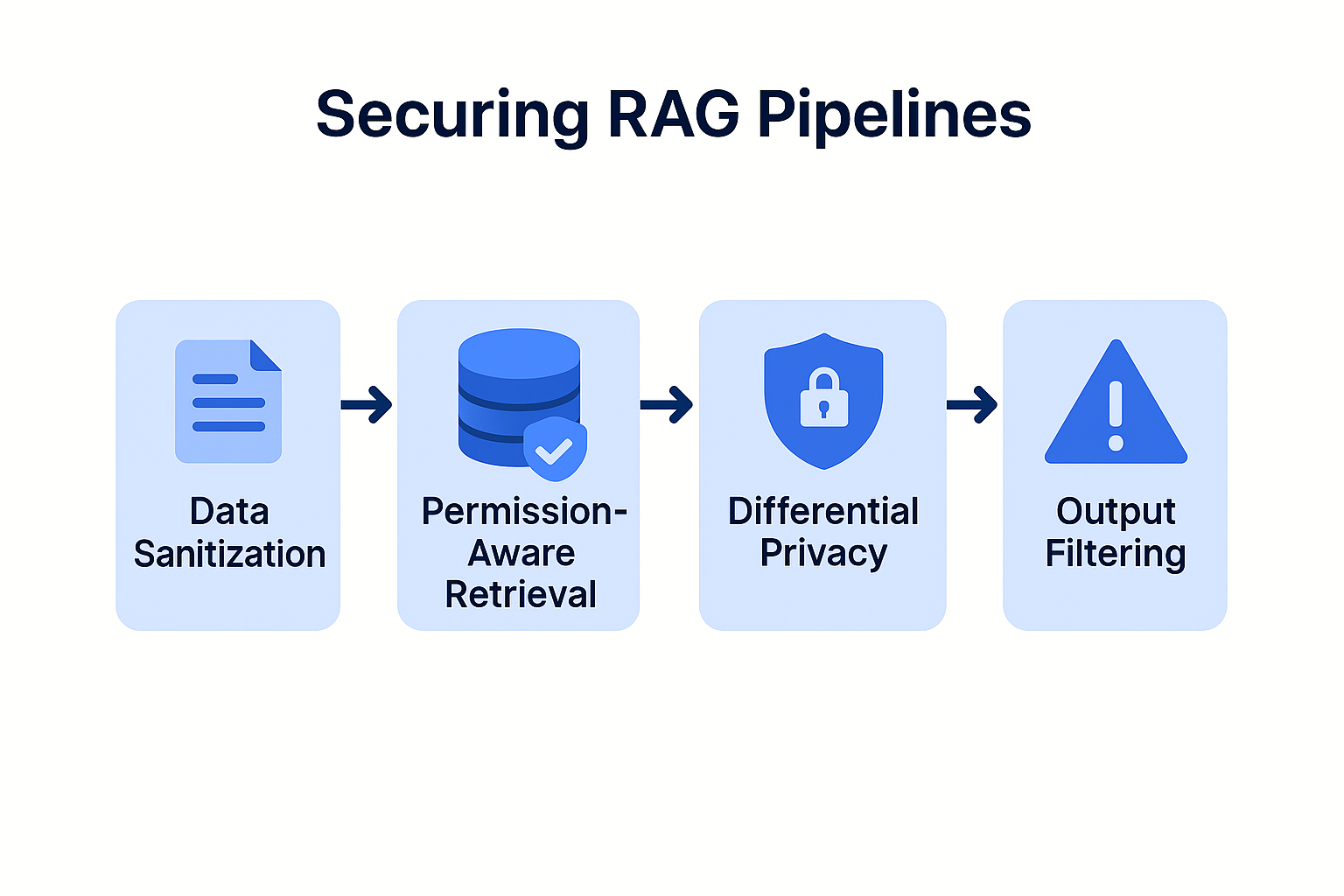
To prevent your AI from becoming a liability, you must secure every stage of the data's journey—from the raw file to the final generated response.
Before a document ever hits your vector database (like Pinecone, Milvus, or Weaviate), it must be scrubbed.
The most common mistake is having a "flat" vector store where every user accesses the same pool of data.
WHERE user_role IN document_acl.If you are fine-tuning a model on proprietary data, you risk the model "memorizing" specific records.
Even if the retrieval is secure, the model might still "hallucinate" sensitive patterns.
Technique. Phase Difficulty Effectiveness
PII Redaction Pre-Processing Medium High (for known patterns)
Metadata Filtering Retrieval High Very High (prevents unauthorized access)
Prompt Masking Input Low Medium (easily bypassed)
Differential Privacy Training Very High High (prevents memorization)
In 2026, leading organizations use a "Two-Pass" RAG system:
[REDACTED_PROJECT_NAME])."Treat your LLM like a highly talented, but extremely gossipy, intern. Only tell them what they absolutely need to know to get the job done."
Securing RAG pipelines is not just about keeping hackers out; it’s about ensuring your AI respects the internal boundaries of your organization. By combining Data Sanitization with Metadata Filtering, you can harness the full power of your data without the fear of disclosure.
Preventing information disclosure is a core pillar of any AI Security Framework. Once your data is safe, the next challenge is ensuring your AI doesn't have "too much power" over your systems.




